Fine, let's tune !
Curiosity
So there I was in curiosity about LLMs (Large Language Models). You know how it goes one minute you're browsing tech blogs, the next you're diving headfirst into the deep end of AI.
I decided to give myself a little challenge.
Here's the task: take a vulnerability description, wait, and bam! Out pops a CWE (Common Weakness Enumeration) that fits like a glove.
Sounds interesting, right?
But I didn't want to take the easy way out (LOL). No regex searches for terms like DOS, XSS, or Code Execution. And forget about using some off-the-shelf algorithm.
My goal? To fine-tune a large language model. It's like teaching an AI to understand security vulnerabilities.
So, there I was, ready to start this journey into AI and Cybersecurity. Who knew that trying to make a computer grasp vulnerabilities could be so intriguing? (me)
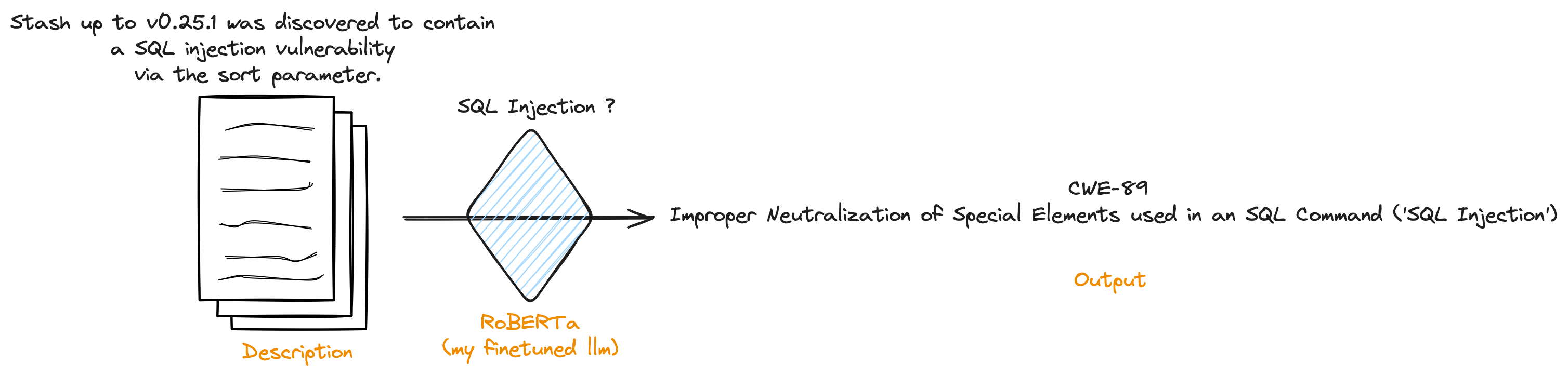
Creating Dataset
First things first, I needed a dataset. It's like teaching a kid math, right? You need to understand the concept yourself and then give them examples to practice on.
In this case, my 'math problem' was classifying vulnerabilities, and I needed descriptions matched with CWEs (Common Weakness Enumerations). Now, here's the tricky part vulnerabilities can often match multiple CWEs. To keep things simple, I decided to focus on the CWE that fit best. You know, like picking your favorite flavor when faced with a triple scoop ice cream cone.
So, where to get this data? Lucky for me, there's MITRE folks who manage the CVE (Common Vulnerabilities and Exposures) numbering system and NIST, who analyze them. My game plan? Grab JSON data for each vulnerability, check if it has a CWE, and if so, get that description for my CSV file.
With the latest updates, there's now a site sharing their entire database as JSON files.
Let's get this dataset done.
# description
text = json_object['cna']['descriptions'][0]['value'].replace('\n', '')
# First CWE
label = json_object['adp'][0]['problemTypes'][0]['descriptions'][0]['description'].replace('\n', '')
# create a new row
final_dataset.append((text, label))After some data struggle (because let's face it, data is never perfect out of the box), I managed to gather 2.6K rows of juicy vulnerability data.
You can check out my dataset here: VulnDesc_CWE_Mapping
For a truly comprehensive dataset, I'd need to analyze and classify the rest of the database. But hey, 2.6K is a pretty solid start for our AI's vulnerability vocabulary lessons, don't you think?

Model Matchmaking Adventure
I've got my dataset all prepped and ready to go. Now comes the fun part choosing which model to fine-tune. I've been hearing buzz about Mistral 7B, Llama 3, GPT...
But here's the thing I'm not looking for a chatty AI buddy. Nope, I need a text-analyzing, classification model.
From my research, I discovered two powerful models called BERT and RoBERTa. Why are they important?
Well, what I'm aiming for is something called Sequence Classification. Fancy name, right? Basically, I need a model that can analyze text, understand its context, and grasp the meaning of each word in its specific setting. It's like teaching AI to comprehend nuances and read between the lines.
These models are called encoders. And when I fine-tune one, I'll be adding a classification layer at the end.
After some digging, I found two encoder models that caught my eye:
RoBERTa (base)
SecureBERT (Bert trained on tech-savvy texts)
My choice goes to RoBERTa, it stands out because of the significant improvements it made over BERT. It optimizes several hyper-parameters, resulting in better performance across various tasks.
Fine Tune it
So, I thought I'd conquered the hardest part. I figured it'd be a breeze to connect everything with a transformers library. Oh, how wrong I was!
Setting up the virtual environment was like trying to solve a Rubik's cube. Dependencies refused to play nice, and I found myself in a tech tango I hadn't signed up for.
Finally, with my virtual environment up and running, it was time to feed my AI some data. Here's the game plan: load the data, split it for evaluation (gotta test our AI's smarts), and tokenize it. Preparing a gourmet meal for our AI to feast on.
train_df, val_df = train_test_split(df, test_size=0.2, random_state=42)
# convert train_df, val_df to Hugging Face datasets and tokenize them
train_dataset = train_dataset.map(tokenize_function, batched=True)
val_dataset = val_dataset.map(tokenize_function, batched=True)Now for the real challenge: TrainingArguments. I started with RoBERTa's standard settings, but my old PC kept throwing 'backend out of memory' errors. It was like trying to fit an elephant into a Mini Cooper. I had to get creative reducing batch size, adding gradient accumulation, and ditching 'fp16=True' which apparently didn't worked with my PC.

After some tweaking, I finally saw those beautiful percentage bars and training logs:
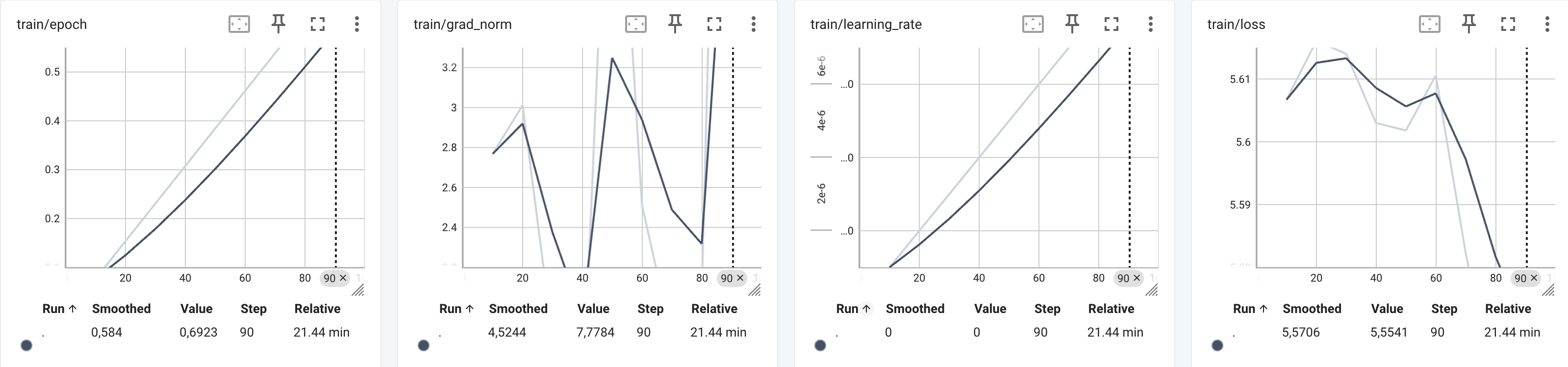
{'loss': 5.647, 'grad_norm': 3.2627339363098145, 'learning_rate': 1.0000000000000002e-06, 'epoch': 0.15}These logs are AI report card, showing how well it's learning. But after the first epoch, I got a scary surprise a 'nan' gradient norm. Smells like trouble, doesn't it?
{'loss': 5.3575, 'grad_norm': nan, 'learning_rate': 1.1000000000000001e-05, 'epoch': 1.69} A 'nan' in the gradient norm is like a check engine light. It could mean exploding gradients or them canceling each other out. Either way, not good for our training stability.
To tackle the 'nan' gradient norm, I made some key adjustments:
- Reduced the learning rate: This slows down the model's parameter updates, helping to prevent drastic changes that could lead to instability.
- Added gradient clipping: By setting a maximum threshold for gradient values, we avoid the 'exploding gradients' problem that can derail training.
- Fine-tuned gradient accumulation: Since I initially used this to compensate for my PC's limited memory, I needed to balance it carefully. Too much accumulation can lead to noisy updates, while too little negates its benefits.
Each parameter plays a crucial role in guiding the model towards optimal performance.
We're back on track:
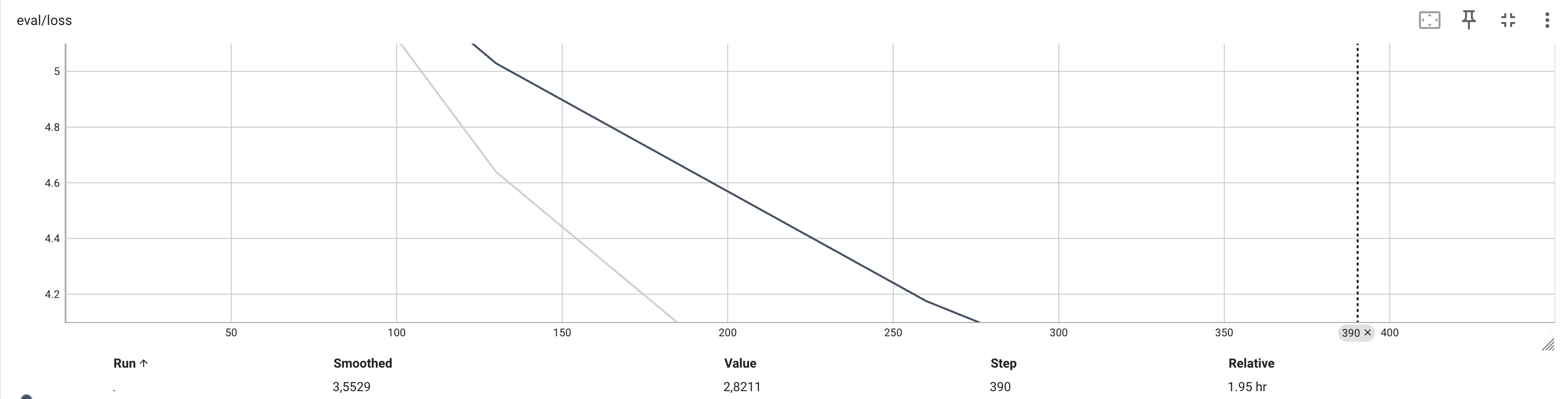
{'loss': 5.6134, 'grad_norm': 3.1113924980163574, 'learning_rate': 3e-06, 'epoch': 0.23} After three epochs, we landed at a training loss of 3.0617 and saw the evaluation loss drop from 4.639444828033447 to 2.821094036102295. For a dataset put together on the fly, I’d call that a win!
The gap between training and evaluation loss suggests our model's got some good generalization skills.
For the data visualization lovers, here are some nifty Tensorboard graphs:
Inference
Alright, so we've trained and tested our model. But the real question is: does it actually make sense in the wild?
I did a simple inference script, just load the model, predict the class, and use a reverse dictionary to print out the proper CWE.
I handpicked 10 vulnerability descriptions. I analyzed these myself first (you know, to set the bar) before letting our AI take a crack at them. And I've got to say, I was pretty impressed!
Sometimes it hits, other times it's a near miss. But here's the kicker even when it doesn't nail it perfectly, its predictions are often justifiable. You can see the logic behind its choices.
Did I mention it's lightning-fast? This AI doesn't mess around it spits out predictions quicker than I can type 'vulnerability'.
Let's take a look at some examples:
| Descriptions | Predictions |
|---|---|
| IBM WebSphere Application Server is vulnerable to cross-site scripting. This vulnerability allows a privileged user to embed arbitrary JavaScript code in the Web UI thus altering the intended functionality potentially leading to credentials disclosure within a trusted session. | CWE-79 Improper Neutralization of Input During Web Page Generation ('Cross-site Scripting') |
| IBM WebSphere Application Server could allow a remote authenticated attacker, who has authorized access to the administrative console, to execute arbitrary code. Using specially crafted input, the attacker could exploit this vulnerability to execute arbitrary code on the system. | CWE-94 Improper Control of Generation of Code ('Code Injection') |
| An improper privilege management vulnerability exists in Tenable Security Center where an authenticated, remote attacker could view unauthorized objects and launch scans without having the required privileges | CWE-284 Improper Access Control |
| This vulnerability allows remote attackers to create a denial-of-service condition on affected installations of Ivanti Avalanche. Authentication is not required to exploit this vulnerability. The specific flaw exists within the WLAvalancheService service, which listens on TCP port 1777 by default. The issue results from dereferencing a null pointer. | CWE-476 NULL Pointer Dereference |
| If a server hosts a zone containing a KEY Resource Record, or a resolver DNSSEC-validates a KEY Resource Record from a DNSSEC-signed domain in cache, a client can exhaust resolver CPU resources by sending a stream of SIG(0) signed requests. | CWE-400 Uncontrolled Resource Consumption |
Where Do We Go From Here?
Reflecting on this journey, I’ve really enjoyed learning the process, from data analysis and creation to fine-tuning the model. It has helped me understand the fine-tuning approach better and opened up new ideas for future projects.
There's always room for improvement. If I were to take this project to the next level, here's my game plan:
- Data Analysis: I need to analyze more descriptions to gather additional data. More data can lead to better performance
- Balanced Examples: Ensuring there are an equal number of examples for each CWE class is important to avoid bias in the model
- Training Parameters: I experienced some random gradient explosions during training, so adjusting the training parameters is essential for stability
- Better Hardware: My current PC has its limits. Using more powerful hardware, like Google Colab, would allow for faster iterations and testing
- Utilizing Probabilities: Since I have tensor probabilities for each input, I can leverage them to focus on the top 'n' predictions.
These are all areas I plan to explore further to deepen my understanding of fine-tuning. I’m looking forward to seeing how these improvements can enhance my work in AI.
If you want to try it yourself, you can find the model here: Kelemia model
